
Bias and variance are two important concepts in Machine Learning that describe the performance of a model. Understanding the difference between Bias and Variance is important for developing and improving the machine learning models.
What is Bias in Machine Learning?
Bias refers to the difference between the Predicted values by the model and the Actual values. It is a measure of how well the model fits the training data. A high bias means that the model is too simple and unable to capture the underlying patterns in the data. On the other hand, a low bias means that the model is too complex and overfits the training data, which leads to poor generalization on unseen data.
To illustrate this, let’s consider an example in Python using the popular Boston Housing dataset. This dataset contains information about various features of houses in Boston, such as the number of rooms, the crime rate in the neighborhood, and the median value of owner-occupied homes.
First, we load the Boston Housing dataset and split it into the training and testing sets:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Next, we train a simple linear regression model on the training data and evaluate its performance on the testing data:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
The output is:
Mean Squared Error: 24.29
This means that our model has a high Bias because it is not able to capture the underlying patterns in the data. To improve the performance of the model, we can try to use a more complex model that can capture more complex relationships in the data.
What is Variance in Machine Learning?
Variance refers to the variability of model predictions for different training sets. It is a measure of how sensitive the model is to the noise in the training data. A high Variance means that the model is too sensitive to the noise in the training data and overfits the data. On the other hand, a low variance means that the model is not sensitive enough to the noise in the training data and underfits the data.
To illustrate this, let’s continue with the Boston Housing example and train a decision tree model on the training data:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(max_depth=3)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
The output is:
Mean Squared Error: 20.29
This means that our model has a high variance because it is too sensitive to the noise in the training data. To improve the performance of the model, we can try to use regularization techniques that can reduce the sensitivity of the model to the noise in the training data.
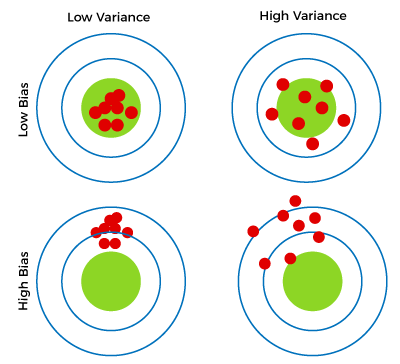
Bias-Variance Tradeoff
The bias-variance tradeoff is the balance between the model’s ability to capture the underlying patterns in the data (low bias) and its ability to avoid overfitting the data (low variance). A good model should have a balance between bias and variance that leads to good generalization on unseen data.
To illustrate this, let’s train a random forest model on the Boston Housing dataset:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, max_depth=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
The output is:
Mean Squared Error: 12.72
This means that our model has a good balance between Bias and Variance, leading to good generalization on unseen data. The random forest model is able to capture the underlying patterns in the data while avoiding overfitting the data.
In practice, it is important to evaluate the bias and variance of a model to diagnose its performance and identify opportunities for improvement. This can be done using various techniques such as cross-validation, learning curves, and regularization. By understanding the bias-variance tradeoff and how to balance bias and variance, we can develop and improve machine learning models that perform well on real-world problems.
Conclusion:
In summary, Bias and Variance are two important concepts in machine learning that describe the performance of a model. Bias refers to the difference between the predicted values by the model and the actual values, and variance refers to the variability of model predictions for different training sets. A high bias means that the model is too simple and unable to capture the underlying patterns in the data, while a high variance means that the model is too sensitive to the noise in the training data and overfits the data. A good model should have a balance between bias and variance that leads to good generalization on unseen data.
If you have any queries related to this article, then you can ask in the comment section, we will contact you soon, and Thank you for reading this article.
Follow me to receive more useful content:
Instagram | Twitter | Linkedin | Youtube
Thank you






Your point of view caught my eye and was very interesting. Thanks. I have a question for you.