Dev Duniya
Mar 19, 2025

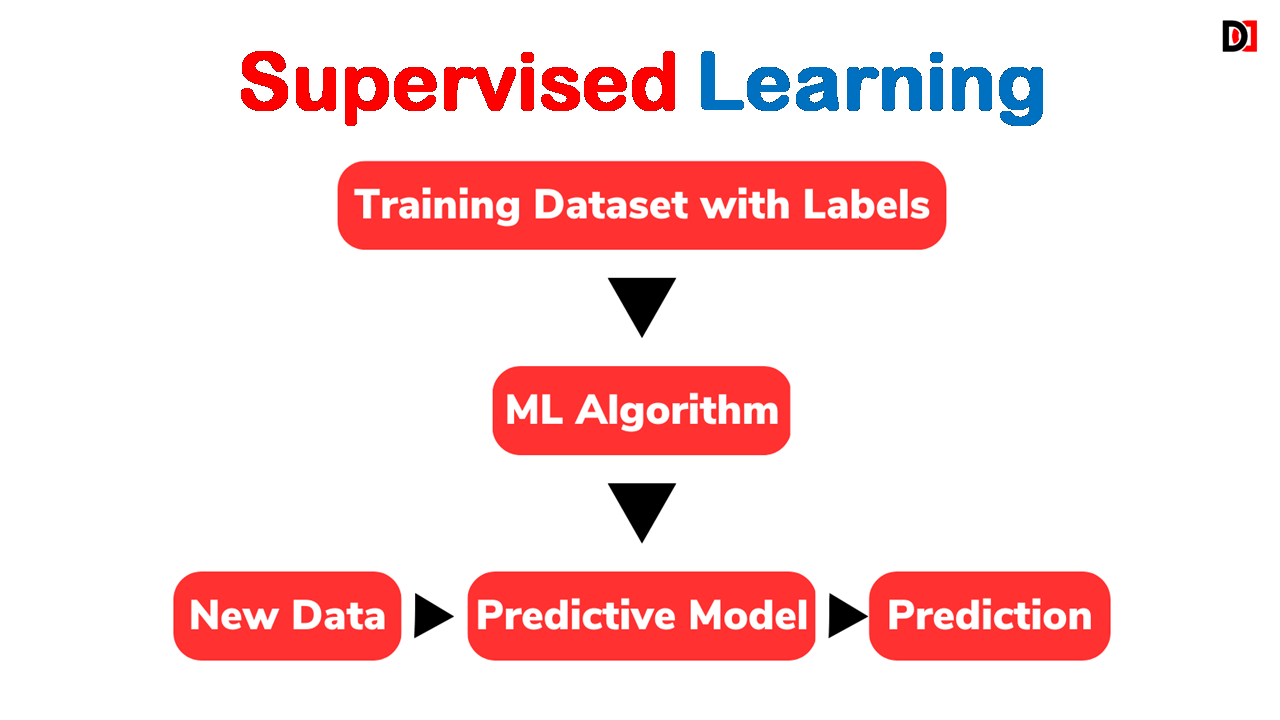
Machine Learning (ML) is a vast field that enables machines to learn from data and make intelligent decisions. It can be broadly categorized into three types: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Let’s explore each of these types in detail.
Supervised learning involves training a model using labeled data, where the input comes with corresponding output labels. The model learns to map inputs to outputs, making predictions on new, unseen data.
Classification is the task of predicting a category or label for a given input based on its features. For example, classifying an email as spam or not spam based on its content or classifying an image as a dog or a cat based on its features.
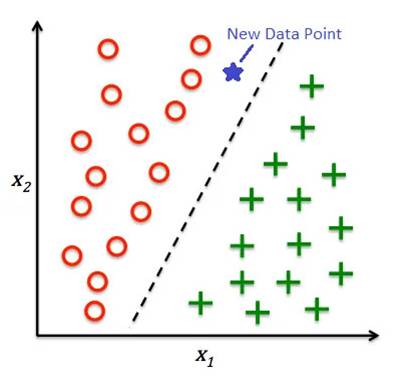
Task: Predict a category or label for given inputs.
Examples: Spam email detection, image classification (dog vs. cat).
Algorithms: Logistic Regression, Decision Trees, Support Vector Machines (SVM), Random Forest.
Regression, on the other hand, is the task of predicting a continuous value for a given input based on its features. For example, predicting the price of a house based on its features such as location, number of bedrooms, etc.
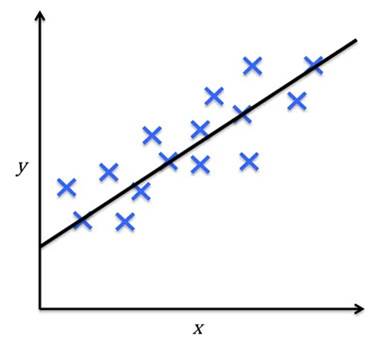
Task: Predict a continuous value based on input features.
Examples: Predicting house prices or stock market trends.
Algorithms: Linear Regression, Gradient Boosting, Decision Trees.
Popular Supervised Algorithms:
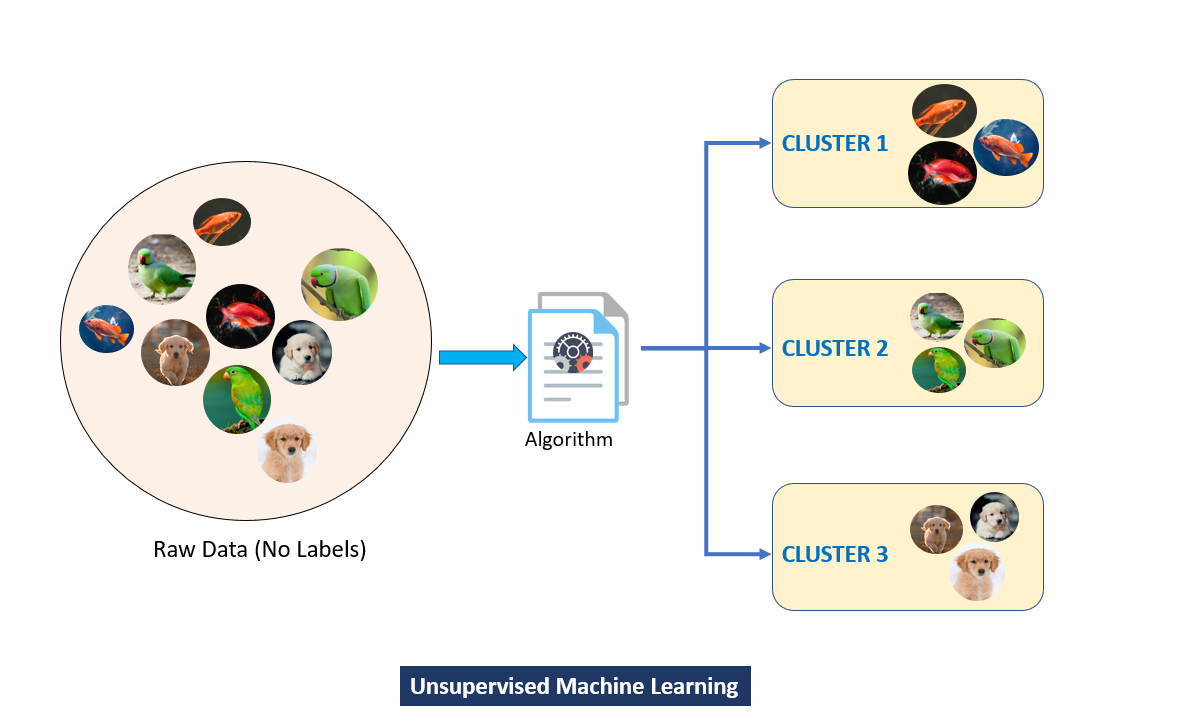
Unsupervised learning trains models on unlabeled data, identifying hidden patterns and relationships without predefined categories.

Clustering is the process of grouping similar data points together based on their features or characteristics. The goal is to find patterns or structure in the data without any predefined categories or labels.

Task: Group similar data points based on features or characteristics.
Examples: Customer segmentation, market basket analysis.
Algorithms: K-Means Clustering, DBSCAN, Mean Shift.
Clustering Example:
Association in unsupervised learning refers to identifying patterns and relationships between variables in a dataset. It involves finding which variables occur together or independently.

Task: Identify relationships or patterns between variables in a dataset.
Examples: Market basket analysis (e.g., customers buying milk often buy bread).
Algorithms: Apriori Algorithm, FP-Growth Algorithm, H-Mine Algorithm.
Dimensionality Reduction is the process of reducing the number of features or variables in a dataset while preserving the most important information. The goal is to simplify the data and make it easier to analyze, visualize or process.
Task: Reduce the number of features in a dataset while preserving essential information.
Examples: Data visualization, preprocessing high-dimensional data for ML models.
Algorithms: Principal Component Analysis (PCA), Autoencoders, Linear Discriminant Analysis (LDA).
Popular Unsupervised Algorithms:
Reinforcement Learning (RL) is a type of ML where an agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties.

Uses a Q-table to store information about the best actions for each state.
A mathematical framework for modeling decision-making problems with probabilistic outcomes.
Applications:
These algorithms are widely used in various domains: