Dev Duniya
Mar 19, 2025

Machine Learning models are designed to learn patterns from data and make predictions or decisions. However, in the quest for better accuracy, they can sometimes learn noise or irrelevant details, leading to overfitting. Regularization is a vital concept in machine learning that helps address this problem, ensuring the models generalize well to unseen data.
In this article, we will explore regularization in detail, covering its importance, techniques, and how it can be implemented effectively. Let's dive in
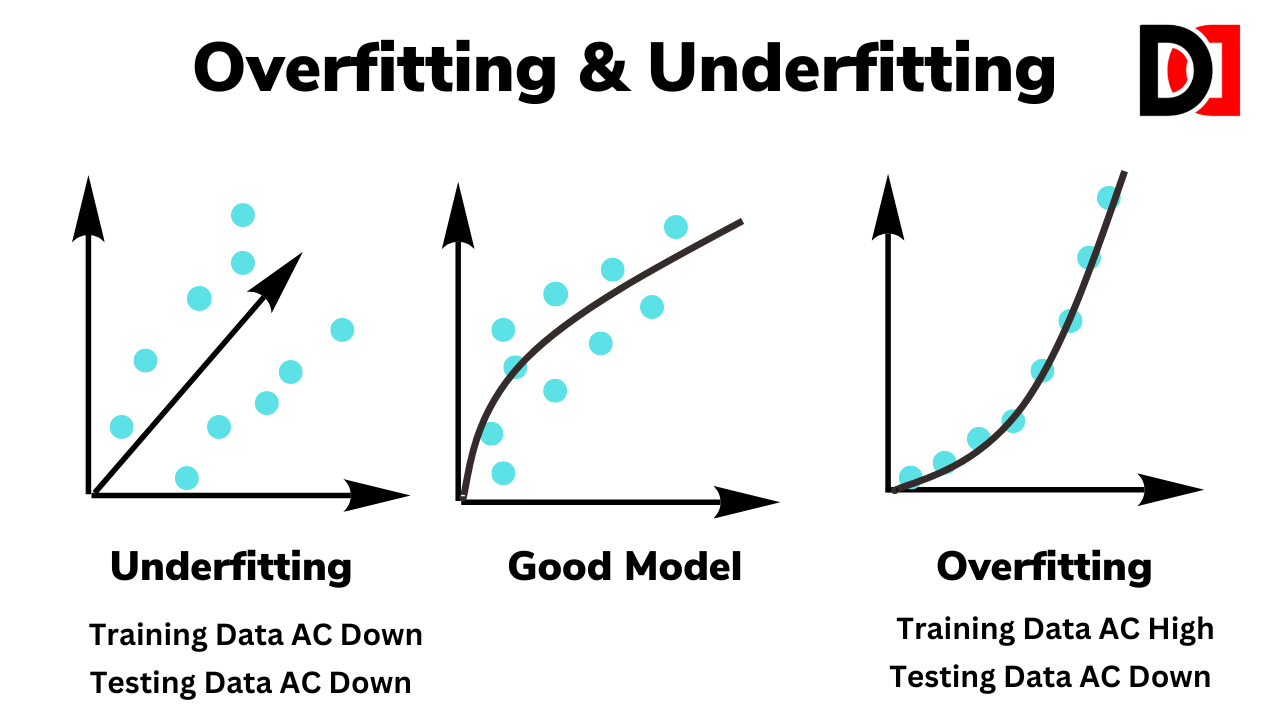
Overfitting is a common challenge in machine learning, where a model performs exceptionally well on the training data but poorly on new, unseen data. This happens because the model has learned the noise and intricacies of the training data too well, failing to generalize to real-world scenarios. Regularization is a powerful technique designed to address this issue.
Regularization is a technique used to prevent overfitting by adding a penalty term to the model’s loss function. This penalty discourages the model from becoming overly complex and helps it focus on the most critical patterns in the data.
By controlling the model's complexity, regularization ensures that it performs well on both the training data and new, unseen data. It effectively balances the trade-off between bias and variance, improving the model's ability to generalize.
Click here to read the complete guide about bias and variance.


L1 regularization adds the absolute value of the coefficients as a penalty term to the loss function. It is defined as:
L2 regularization adds the square of the coefficients as a penalty term to the loss function. It is defined as:
Elastic Net combines L1 and L2 regularization, adding both absolute and squared penalties:
Dropout is a regularization technique specifically for neural networks. It randomly "drops out" or ignores certain neurons during training, preventing co-dependencies among neurons.
Early stopping is a simple and effective regularization technique. It involves monitoring the model’s performance on a validation set and halting training when the performance stops improving.
Data augmentation increases the diversity of the training data by applying transformations, such as rotations, translations, and noise.
Weight constraints limit the magnitude of weights during training. Examples include max norm constraints and unit norm constraints.
Batch normalization normalizes input features for each batch during training. While not explicitly a regularization technique, it has a regularizing effect by reducing internal covariate shift.
Adding noise to inputs, weights, or activations during training can act as a form of regularization.
| Aspect | Ridge | Lasso | Elastic Net |
|---|---|---|---|
| Penalty Type | L2 | L1 | L1 + L2 |
| Feature Selection | No | Yes | Yes |
| Multicollinearity | Handles Well | Struggles | Handles Well |
| Coefficients | Shrinks | Some to Zero | Combination |
Click here to read the complete guide about Overfitting and Underfitting.
The choice of regularization technique depends on the model, dataset, and problem:
Here are examples of implementing regularization in Python:
from sklearn.linear_model import Lasso, Ridge
# Lasso (L1 Regularization)
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
# Ridge (L2 Regularization)
ridge = Ridge(alpha=1.0)
ridge.fit(X_train, y_train)from tensorflow.keras.layers import Dropout
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # Dropout rate of 50%from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
model.fit(X_train, y_train, validation_data=(X_val, y_val), callbacks=[early_stopping])Regularization is a cornerstone of building robust and generalizable machine learning models. By penalizing complexity, it ensures that models focus on meaningful patterns in the data and avoid overfitting. Whether you’re working with simple regression or complex neural networks, understanding and applying regularization techniques is essential for achieving optimal performance.