Dev Duniya
Mar 19, 2025

Machine learning models rely heavily on the quality and consistency of data. One critical step in data preprocessing is ensuring that the features in the dataset are properly scaled. This process can significantly affect the performance of the model. In this blog, we'll dive deep into Normalization, Scaling, and Standardization, explaining their concepts, differences, and when to use each technique.
Data scaling is the process of transforming data into a specific range or distribution to ensure all features contribute equally to the model. It is particularly important for machine learning algorithms that rely on the distance between data points, such as:
Without scaling, features with larger numerical ranges could dominate the learning process, making the model biased and less accurate.
Normalization is the process of adjusting the values of a feature to a range between 0 and 1. It is a type of scaling where we transform data to make it fit within a specific scale while preserving the relationships between the data points.

Normalization is best used when:
| Feature | Raw Value | Normalized Value |
|---|---|---|
| Feature 1 | 10 | 0 |
| Feature 1 | 15 | 0.33 |
| Feature 1 | 20 | 0.67 |
| Feature 1 | 30 | 1 |
Standardization transforms data to have a mean of 0 and a standard deviation of 1. It centers the data and rescales it based on the standard deviation.
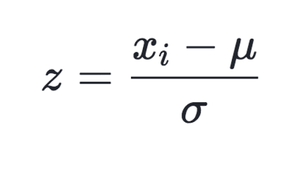
Where:
Standardization is used when:
| Feature | Raw Value | Standardized Value |
|---|---|---|
| Feature 1 | 10 | -1.14 |
| Feature 1 | 15 | -0.71 |
| Feature 1 | 20 | 0 |
| Feature 1 | 30 | 1.14 |
Scaling adjusts the magnitude of data without changing its distribution. It ensures that all features contribute equally to the model by fitting them within a specific range or distribution.
| Aspect | Normalization | Standardization | Scaling |
|---|---|---|---|
| Purpose | Fit data in a fixed range, e.g., 0 to 1. | Center data to have mean = 0, std dev = 1. | Adjust magnitude without changing distribution. |
| Best For | Neural Networks, KNN, SVM. | PCA, Logistic/Linear Regression. | Situations requiring general adjustments. |
| Sensitivity to Outliers | Sensitive | Less Sensitive | Depends on the scaling method. |
Here's a simple example of how to use each technique in Python using the scikit-learn library.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaled_data = scaler.fit_transform(data)
Normalization, scaling, and standardization are essential preprocessing steps in machine learning. Understanding their nuances and applying them correctly can drastically improve your model's performance. Always analyze your data and choose the method that best aligns with your algorithm and data distribution.