Dev Duniya
Mar 19, 2025

Clustering is a fundamental concept in machine learning that plays a pivotal role in understanding and organizing data. Whether you are exploring customer segmentation, document classification, or anomaly detection, clustering techniques are often the go-to solution. This blog will delve deep into clustering, its types, algorithms, and their applications, helping you grasp its significance in the machine learning landscape.
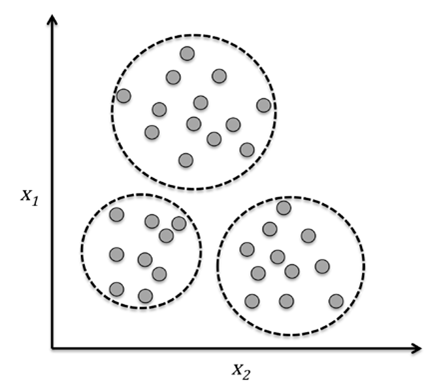
Clustering is an unsupervised learning technique used to group similar data points into clusters. Unlike supervised learning, where the data comes with labeled outputs, clustering relies purely on the inherent structure of the data. The goal is to ensure that data points within a cluster are similar to each other while being distinct from those in other clusters. For example, in marketing, clustering can help identify groups of customers with similar purchasing habits.
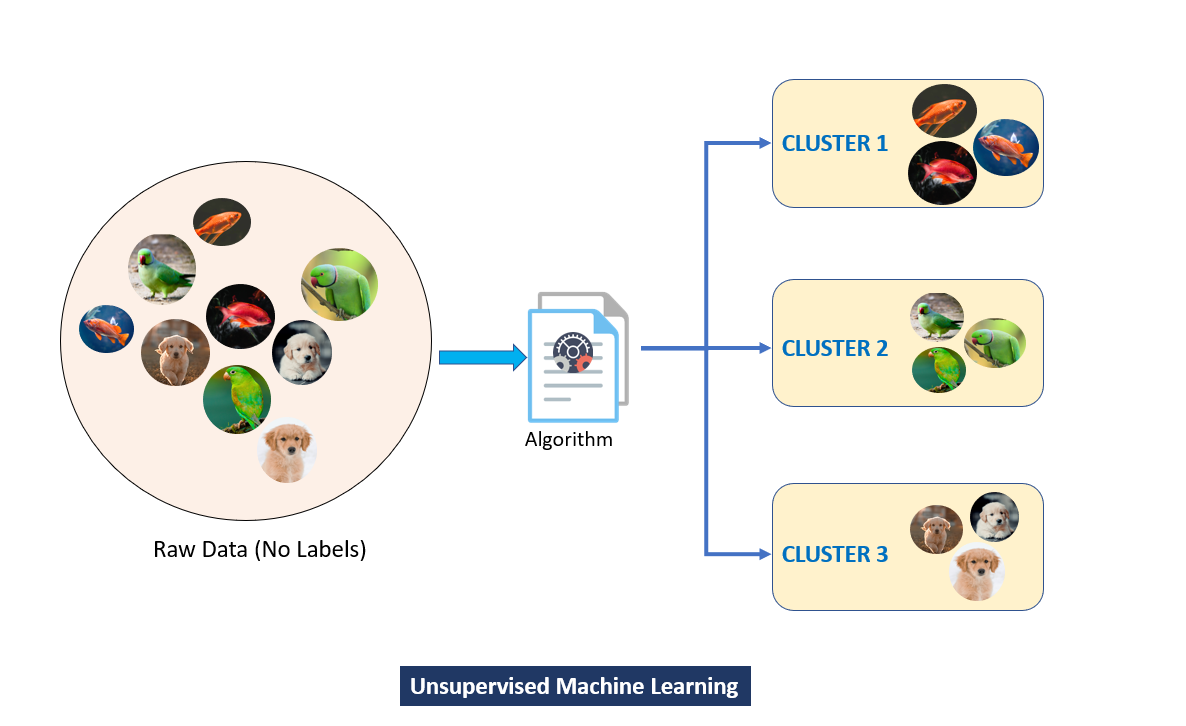
Clustering techniques can be broadly categorized based on their approach to grouping data:
Each of these approaches offers unique advantages and challenges, making them suitable for different types of datasets.
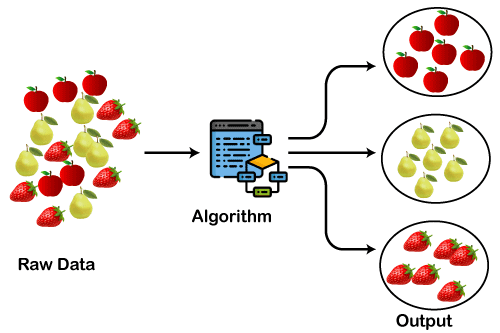
Clustering algorithms are the tools used to implement the above techniques. Let’s explore some popular ones:
Hierarchical Clustering: Builds a tree-like structure by recursively merging or splitting clusters. It can be agglomerative (bottom-up) or divisive (top-down).
K-Means Clustering: Partitions the data into a pre-defined number of clusters. It iteratively adjusts the centroids to minimize intra-cluster variance.
Gaussian Mixture Models (GMMs): Based on the assumption that data is generated from a mixture of several Gaussian distributions, each representing a cluster.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Groups data points that are closely packed together while identifying outliers as noise.
K-Means is perhaps the most popular clustering algorithm due to its simplicity and efficiency. It starts by initializing K cluster centroids and iteratively assigns data points to the nearest centroid, updating their positions until convergence. Despite its popularity, K-Means is sensitive to the initial placement of centroids and assumes clusters are spherical.
Hierarchical clustering organizes data into a dendrogram, a tree-like structure. The algorithm doesn’t require pre-defining the number of clusters, making it versatile. However, its computational cost can be prohibitive for large datasets.
| Aspect | K-Means | Hierarchical Clustering |
|---|---|---|
| Cluster Shape | Spherical | Any Shape |
| Scalability | High | Low |
| Number of Clusters | Pre-defined | Determined by the algorithm |
| Algorithm Type | Iterative | Recursive |
Clustering has applications across industries:
Clustering can enhance supervised learning in several ways:
A non-parametric algorithm that identifies dense regions in the data. It’s versatile and doesn’t require pre-specifying the number of clusters but can be computationally expensive.
Ideal for datasets with varying densities, DBSCAN excels at identifying outliers. It’s robust but struggles with datasets containing clusters of differing sizes.
Optimized for large datasets, BIRCH builds a clustering feature tree to summarize the data, making it faster and more scalable.
Clustering is a cornerstone of machine learning, offering powerful tools for uncovering patterns in data. From simple techniques like K-Means to advanced methods like DBSCAN and BIRCH, each algorithm has its strengths and weaknesses. Understanding these nuances enables practitioners to select the right approach for their data. Whether you’re enhancing supervised learning or solving real-world problems, clustering remains an indispensable part of the machine learning toolkit.