
Ensemble Learning is a powerful technique in machine learning that combines multiple individual models (often called “weak learners”) to create a stronger, more accurate model. This “wisdom of the crowd” approach leverages the strengths of different models to improve overall performance.
First Level of ML (Weak Learners):
A weak learner is a model that gives better results than a random prediction in a classification problem or the mean in a regression problem.
- Linear Regression
- Logistic Regression
- Support Vector Machines
- Decision Trees
- Naive Bayes
Ensemble Learning(Strong Learner):
Ensemble Learning is a technique where multiple machine learning models are combined to make better predictions than a single model could on its own.
- Voting
- Bagging
- Pasting
- Stacking
- Boosting
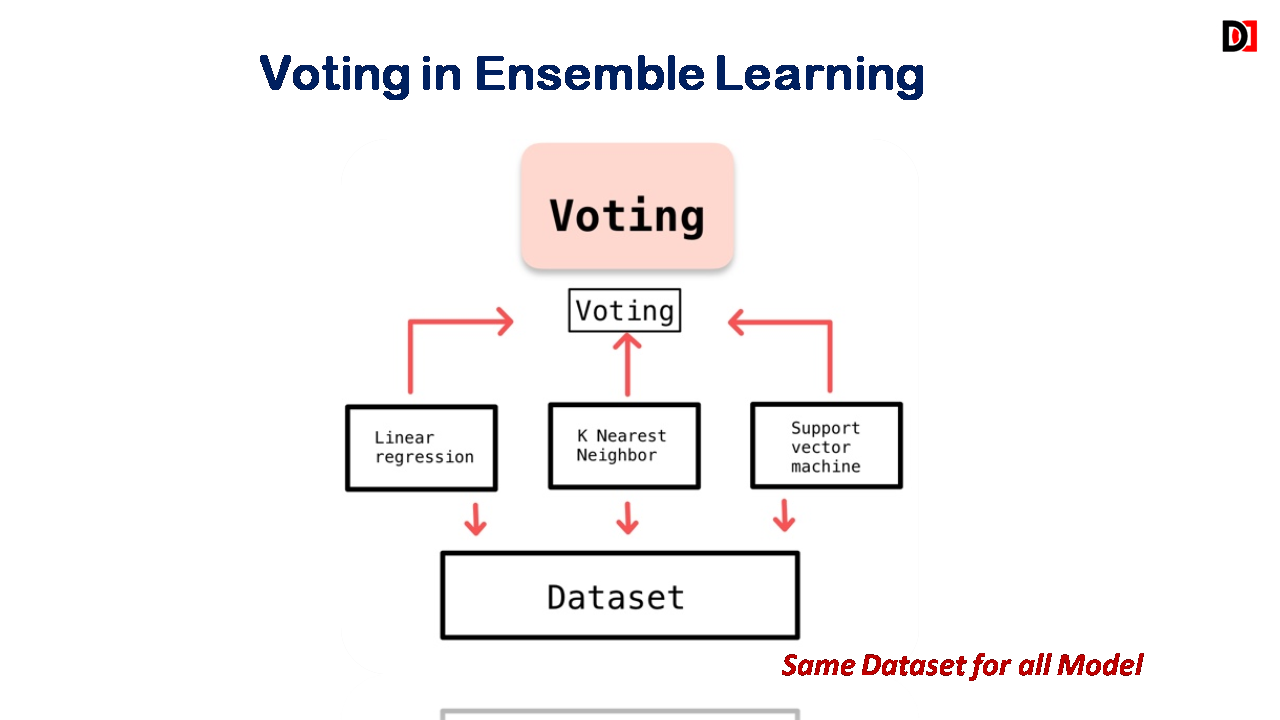
Voting in Ensemble Learning:
Combines predictions from multiple models by simple voting (majority vote) or weighted voting (where some models have more influence).
Examples:
- Majority Voting: Each model casts a vote, and the class with the most votes wins.
- Weighted Voting: Models are assigned weights based on their individual performance.
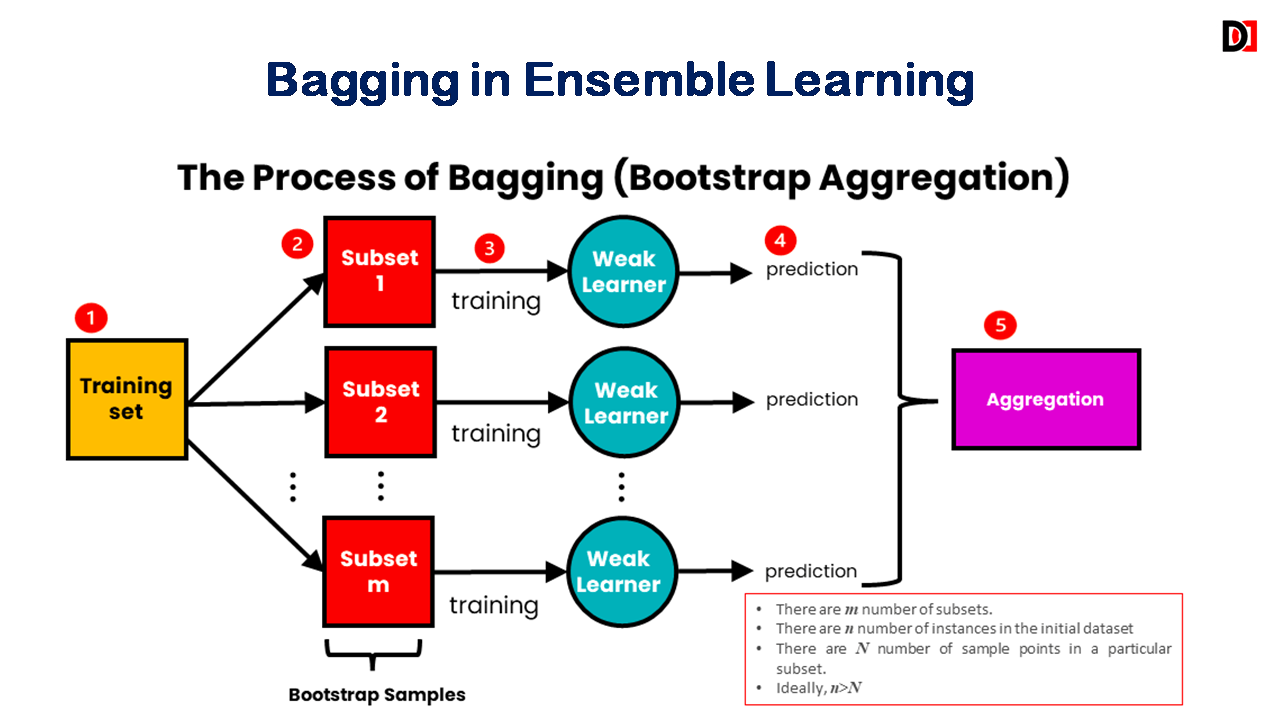
Bagging (Bootstrap Aggregating):
- Creates multiple models by training them on different subsets of the training data.
- Subsets are created by sampling with replacement (bootstrapping), meaning some data points may appear multiple times in a subset.
- Reduces variance by improving model stability.
Examples:
- Random Forest: An ensemble of decision trees.
- Extra Trees: Similar to Random Forest, but uses random feature subsets.
Bagging in Ensemble Learning:
- Out of Bag (OOB): In bagging methods, some data points might not be included in certain subsets. These “out of bag” data points can be used to evaluate the model’s performance without needing a separate validation set.
- Inside Bag: Inside bag data points are the ones included in the subsets used for training the models. They contribute to building individual models in the ensemble.
- Replacement: When creating subsets for bagging, replacement means that a data point can appear in multiple subsets.
- Without Replacement: Without replacement means that a data point can only appear in one subset.
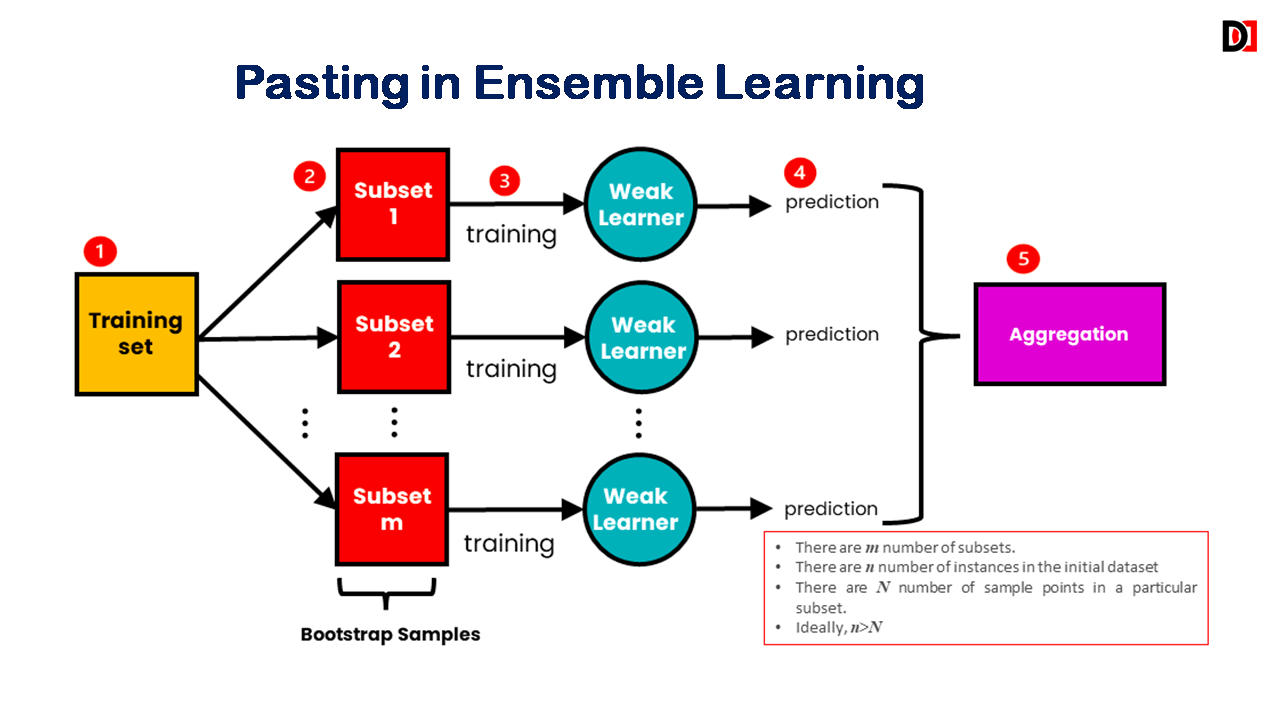
Pasting
- Similar to bagging, but creates subsets without replacement.
- Each data point appears in only one subset.
- Generally less prone to overfitting than bagging.
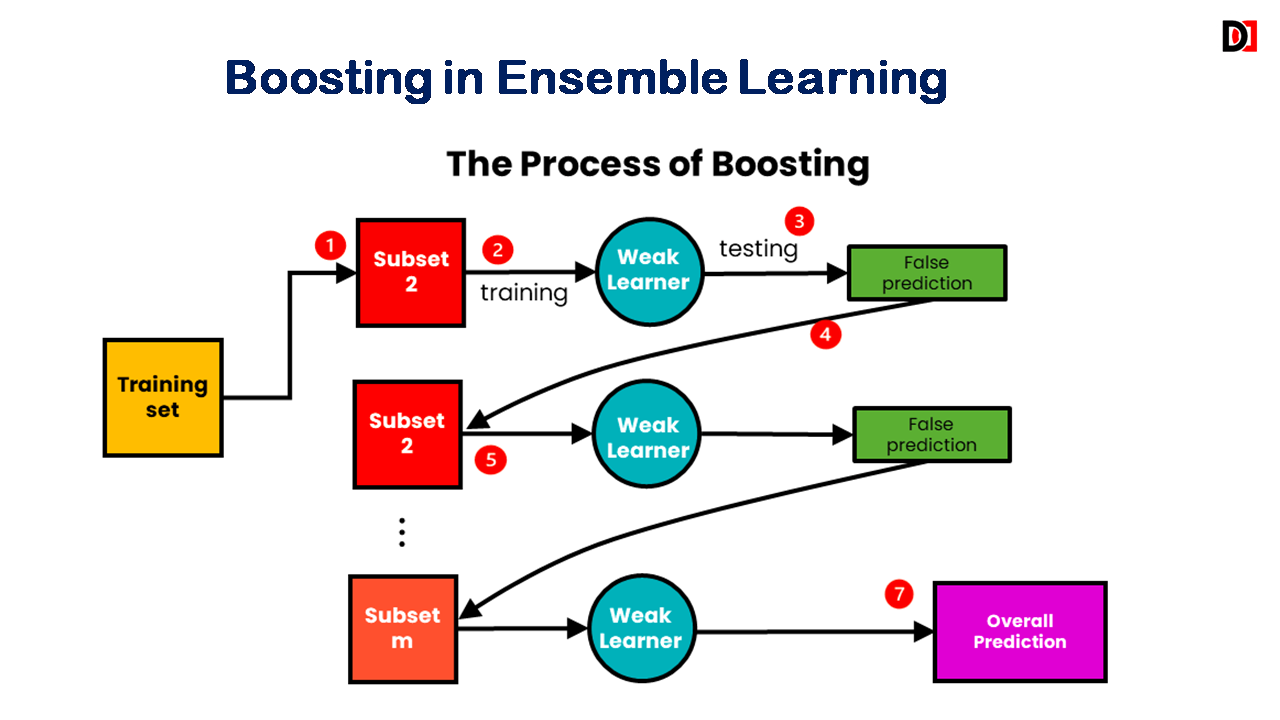
Boosting
Sequentially trains a series of weak learners, where each subsequent model focuses on correcting the errors of the previous ones.
Examples:
- AdaBoost (Adaptive Boosting): Assigns weights to training examples, giving more weight to misclassified examples.
- Gradient Boosting: Trains models sequentially, where each new model learns to correct the residuals (errors) of the previous models.
- XGBoost (Extreme Gradient Boosting): An optimized and efficient implementation of gradient boosting.
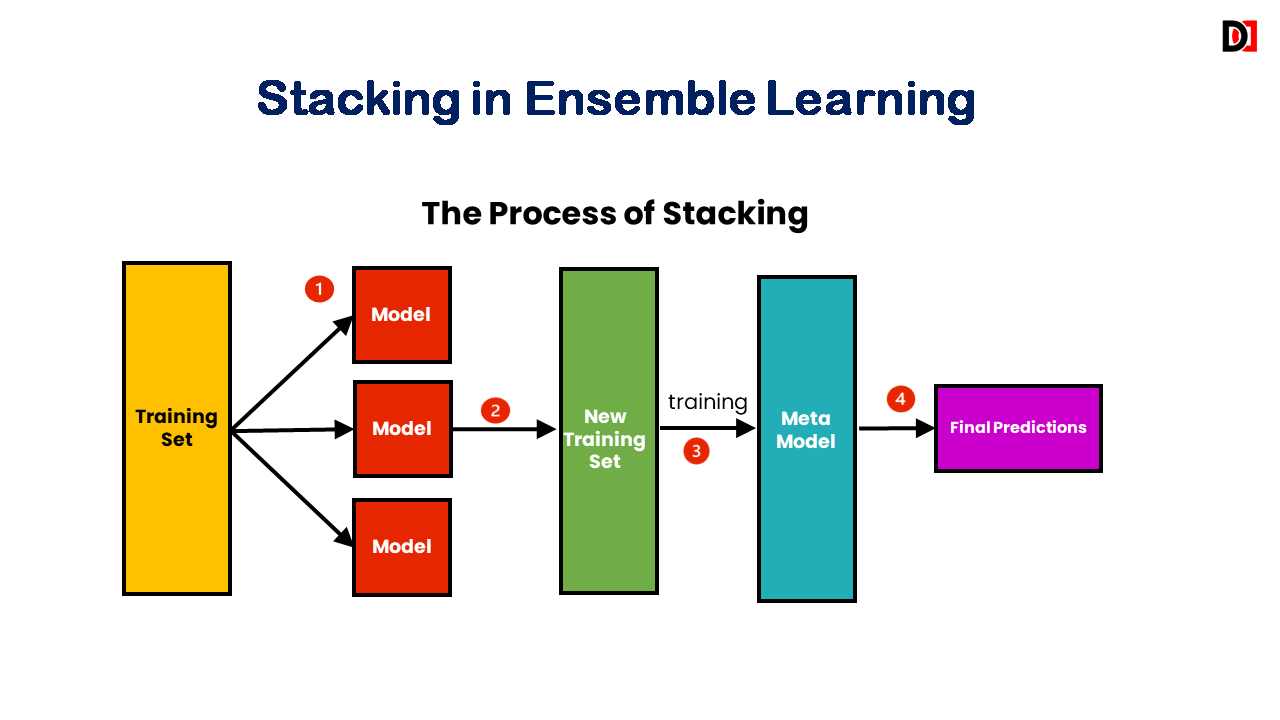
Stacking
- Trains a “meta-learner” (e.g., a linear regression model, logistic regression) on the predictions of multiple base models.
- The meta-learner learns to combine the predictions of the base models to make the final prediction.
Key Advantages of Ensemble Learning:
- Improved Accuracy: Often achieves higher accuracy than individual models.
- Reduced Overfitting: Ensembles can help to reduce overfitting by averaging out the noise and improving generalization.
- Increased Robustness: Ensembles are less sensitive to variations in the training data.
Example (Simplified – Bagging with Decision Trees)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a Bagging classifier with Decision Trees as base estimators
bagging_clf = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=100,
random_state=42
)
# Train the model
bagging_clf.fit(X_train, y_train)
# Make predictions
y_pred = bagging_clf.predict(X_test)
# Evaluate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Ensemble Learning is a powerful technique that can significantly improve the performance of machine learning models. By combining the strengths of multiple models, 1 ensembles can achieve higher accuracy, better robustness, and improved generalization.





