
In the world of machine learning, building a model that performs well on unseen data is paramount. This is where Cross-Validation comes into play. It’s a powerful technique that helps us evaluate how well our model will generalize to new, previously unseen data.
What is Cross-Validation?
Imagine you’re baking a cake. You test a small piece of the cake to see if it’s baked through. Cross-validation is similar. We essentially “bake” our model on a portion of the data (training) and then “taste” how well it performs on a different portion (testing).
Here’s the gist:
- Divide and Conquer: We divide our dataset into multiple subsets (folds).
- Train and Test: We repeatedly train the model on a portion of the data and evaluate its performance on the remaining portion.
- Average Performance: By averaging the performance across all iterations, we get a more robust estimate of the model’s true performance.
Why is Cross-Validation Important?
- Overfitting Detection: Cross-validation helps us identify if our model is overfitting. Overfitting occurs when the model performs exceptionally well on the training data but poorly on new data.
- Hyperparameter Tuning: It allows us to tune hyperparameters (e.g., learning rate, number of trees in a random forest) to find the optimal configuration for our model.
- Model Selection: Cross-validation helps us compare different models and select the one that performs best on unseen data.
Types of Cross-Validation:
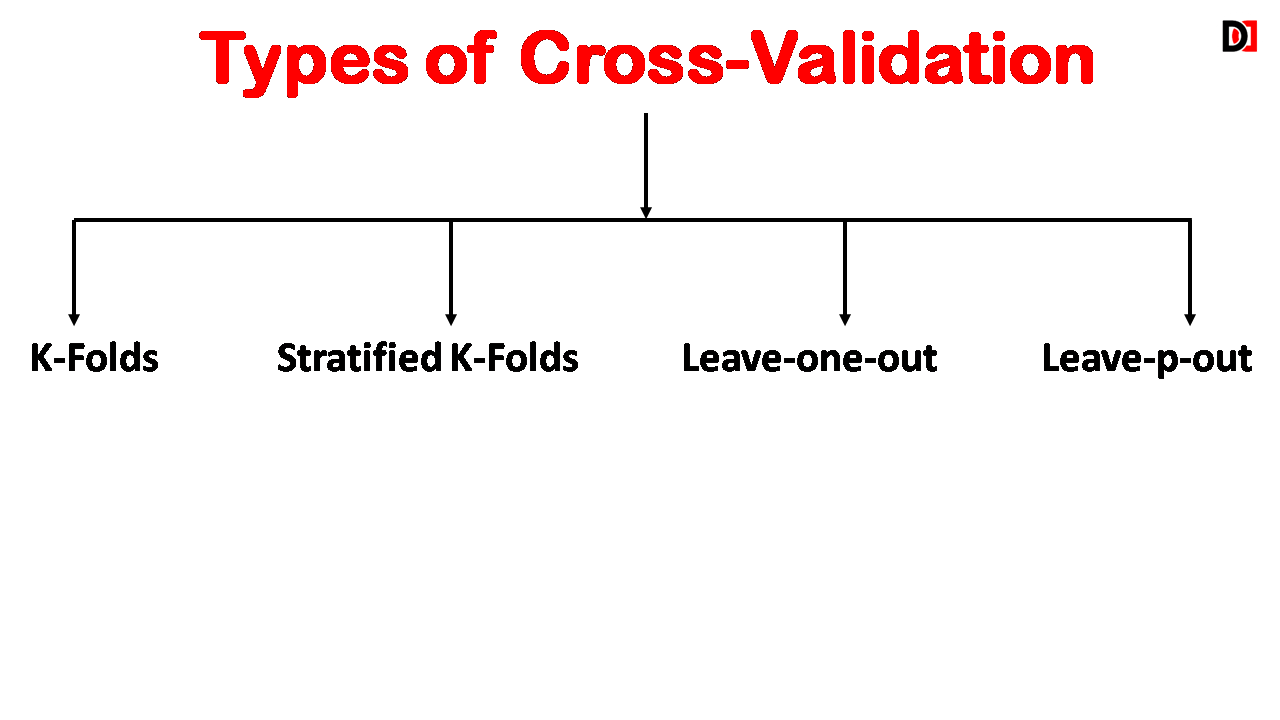
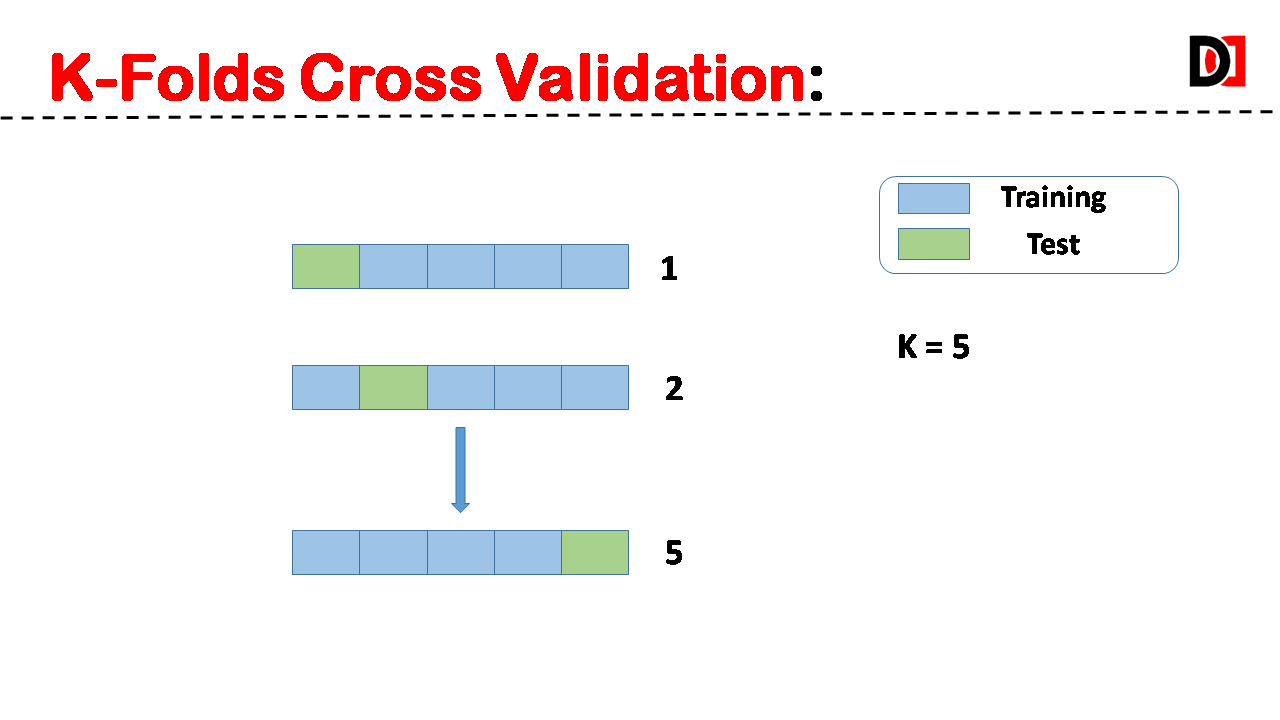
1. K-Folds:
The dataset is divided into ‘k’ equal-sized folds. The model is trained on ‘k-1’ folds and evaluated on the remaining fold. This process is repeated ‘k’ times, with each fold 1 serving as the validation set once.
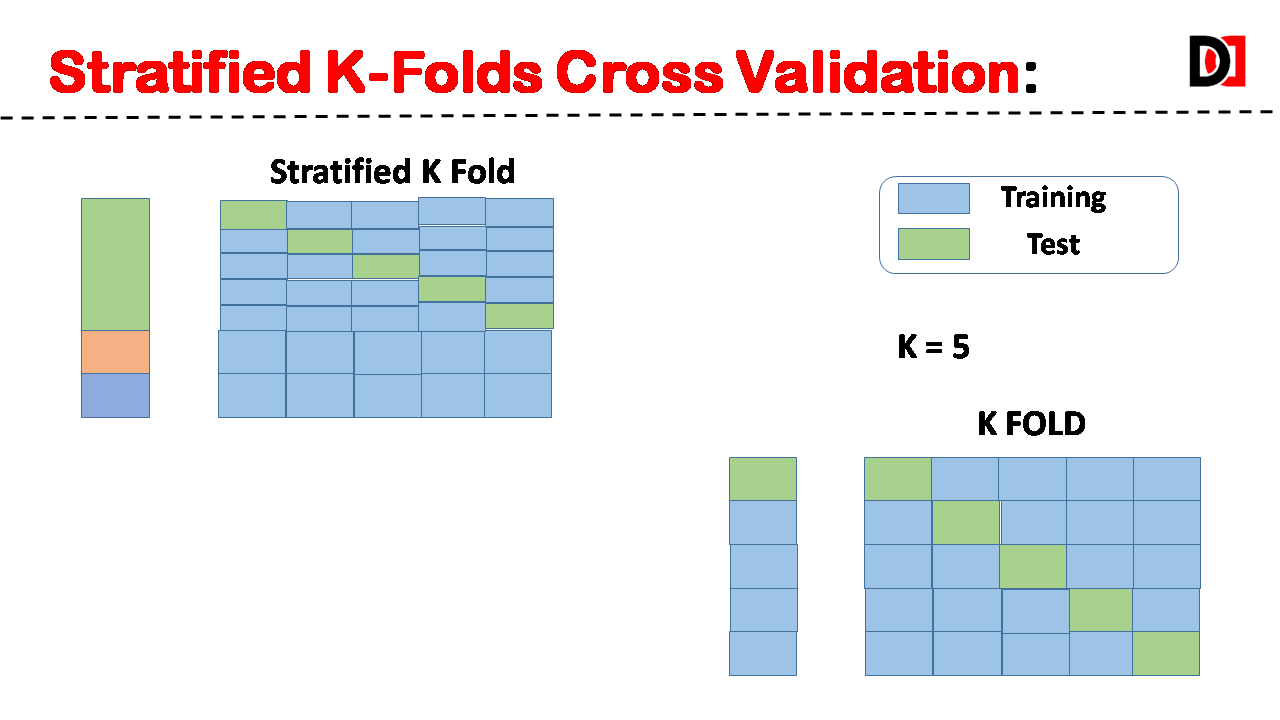
2. Stratified K-Folds:
Similar to K-Folds, but ensures that the proportion of different classes (in classification problems) is maintained in each fold. This is crucial when dealing with imbalanced datasets.
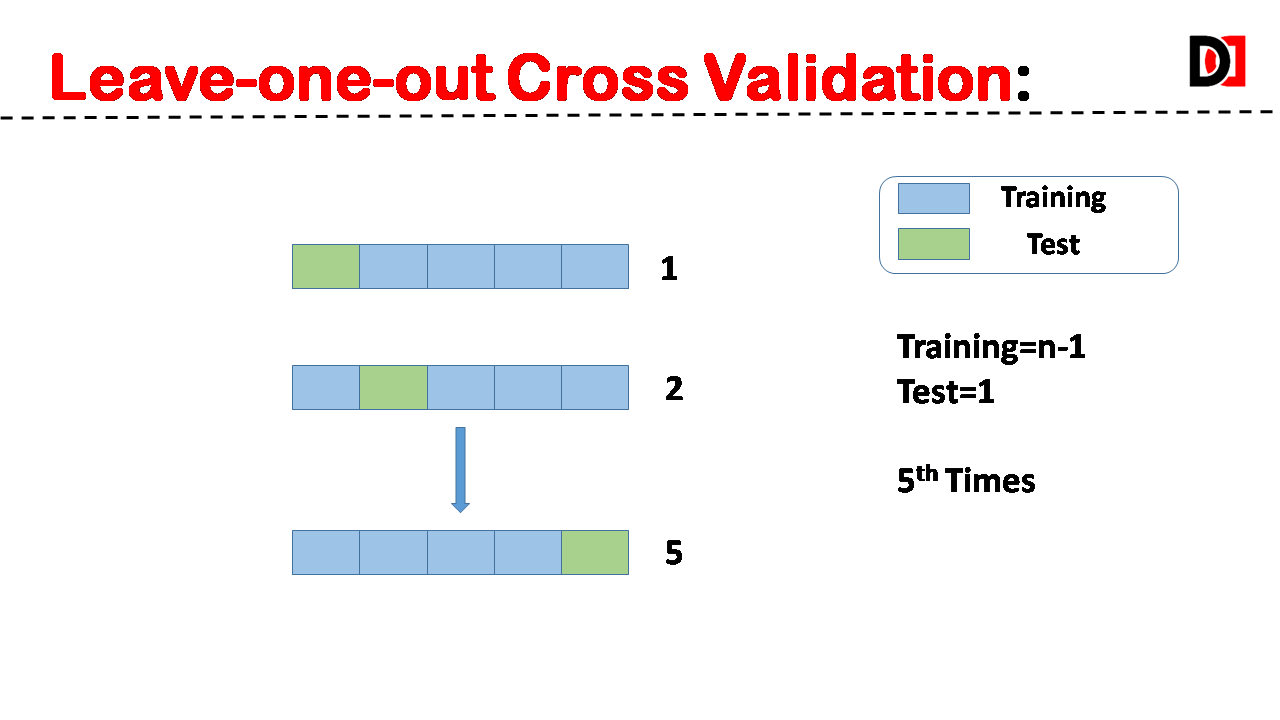
3. Leave-One-Out Cross-Validation (LOOCV):
In this extreme case, ‘k’ is equal to the number of data points. Each data point is used as the validation set once, while the remaining data is used for training.
4. Leave-P-Out Cross-Validation:
A subset of ‘p’ data points is used as the validation set, while the remaining data is used for training. This process is repeated for all possible combinations of ‘p’ data points.
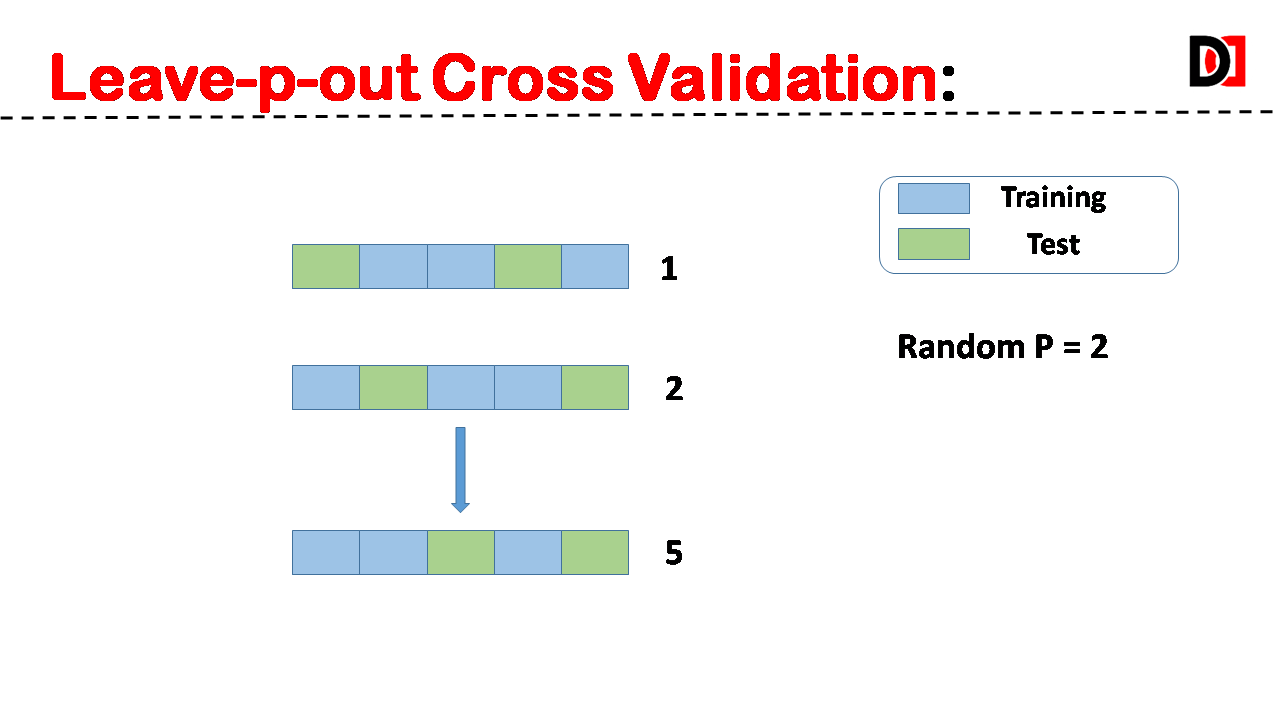
Choosing the Right Cross-Validation Technique
The choice of cross-validation technique depends on factors such as:
- Dataset size: LOOCV is computationally expensive for large datasets.
- Class imbalance: Stratified K-Folds is crucial for imbalanced datasets.
- Computational resources: The available computational resources will influence the choice of ‘k’ in K-Folds.
By understanding and effectively applying cross-validation techniques, you can build more robust and reliable machine learning models that generalize well to unseen data.





