
In machine learning, the quality of the data used plays a crucial role in the success of the model. To effectively train, evaluate, and optimize a model, the dataset is typically divided into three subsets:
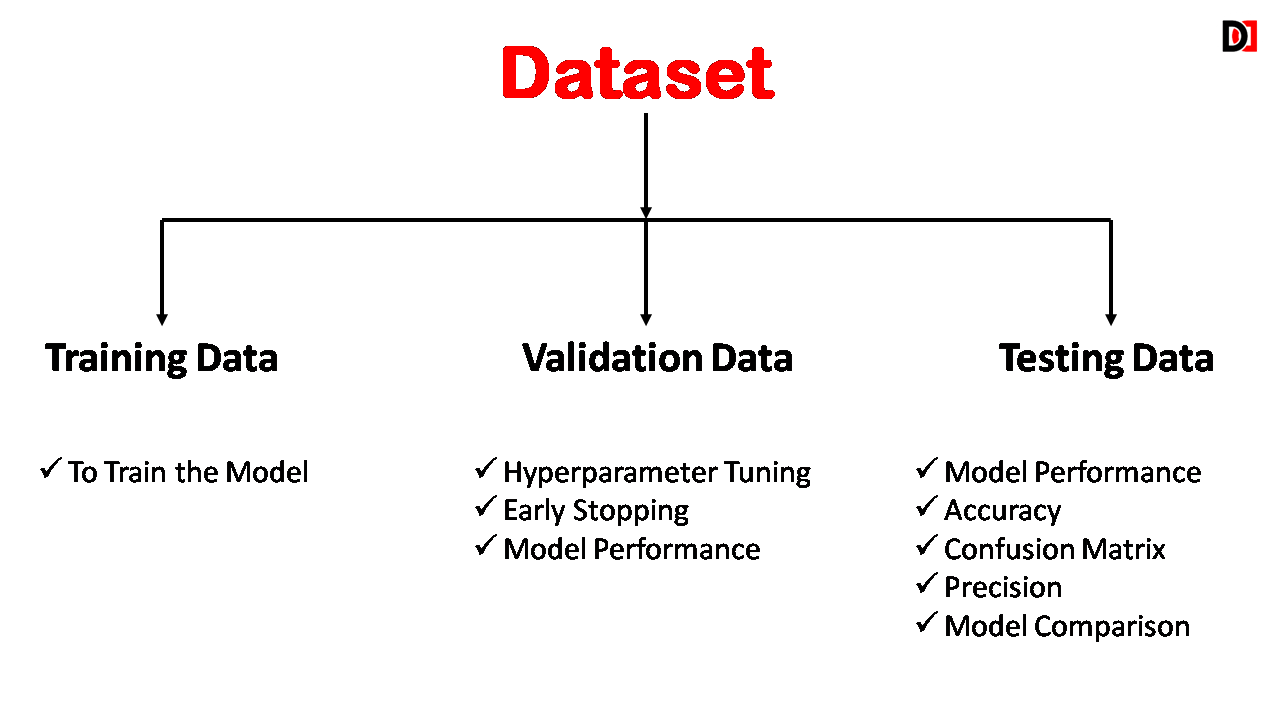
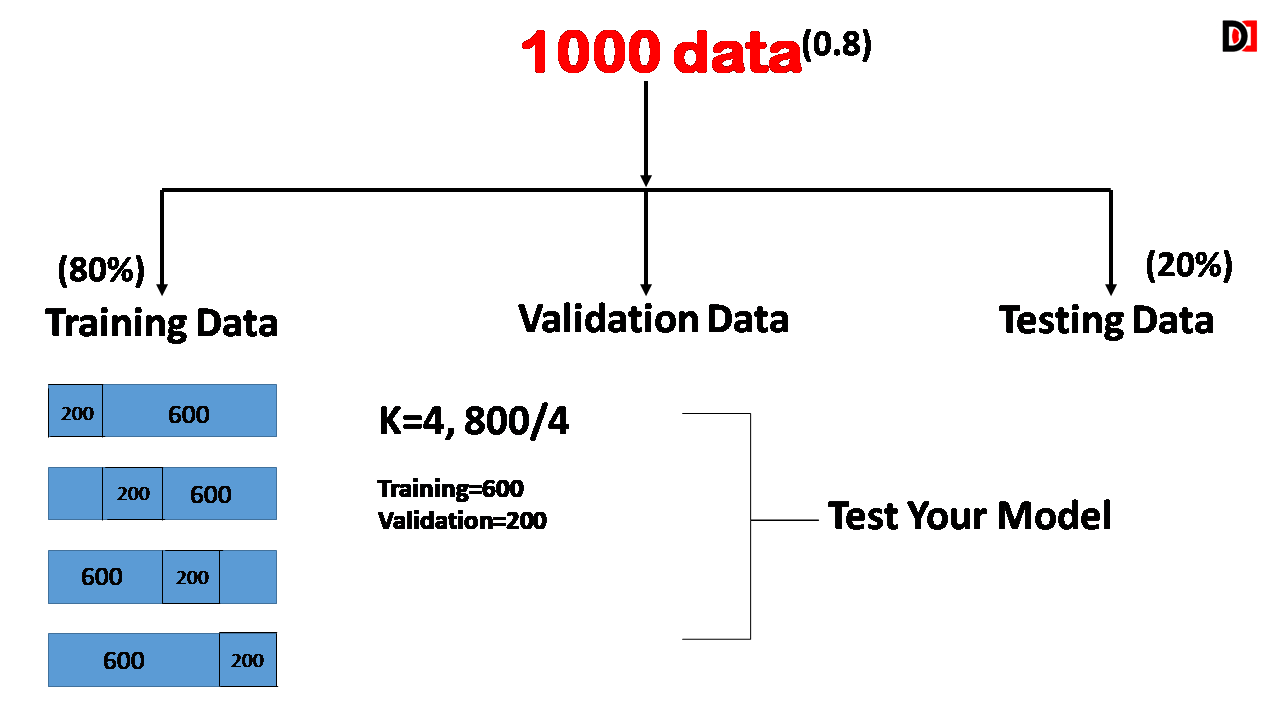
1. Training Dataset
- Purpose: This is the primary dataset used to train the machine learning model.
- Function: The model learns patterns and relationships within the training data during the training process.
- Characteristics:
- Should be representative of the real-world data the model will encounter.
- Should contain a sufficient number of examples with diverse characteristics.
- Should be free from significant biases or errors.
2. Testing Dataset
- Purpose: This dataset is used to evaluate the performance of the trained model on unseen data.
- Function: It provides an unbiased assessment of how well the model generalizes to new, previously unseen examples.
- Characteristics:
- Should be completely independent from the training dataset.
- Should be representative of the real-world data the model will encounter.
- Used to calculate metrics like accuracy, precision, recall, F1-score, etc.
3. Validation Dataset
- Purpose: This dataset is used to tune the model’s hyperparameters and prevent overfitting.
- Function: It helps to select the best model configuration and avoid overfitting to the training data.
- Characteristics:
- Should be separate from both the training and testing datasets.
- Should be representative of the real-world data.
- Used to monitor the model’s performance during training and select the best set of hyperparameters.
Why is this division important?
- Preventing Overfitting: By using a separate validation set, we can monitor the model’s performance on unseen data during training. This helps to identify and prevent overfitting, where the model performs well on the training data but poorly on new data.
- Selecting Optimal Hyperparameters: The validation set allows us to experiment with different model configurations (e.g., different values for learning rate, regularization strength) and select the hyperparameters that result in the best performance.
- Unbiased Evaluation: The testing dataset provides an unbiased evaluation of the final model’s performance on completely unseen data, giving a realistic assessment of its real-world capabilities.
The careful division of data into training, validation, and testing sets is crucial for building robust and reliable machine learning models. By using these datasets effectively, we can ensure that our models generalize well to new data and achieve optimal performance.





